- Декартово дерево
- Операции в декартовом дереве
- split
- Псевдокод
- Время работы
- merge
- Псевдокод
- Время работы
- insert
- remove
- Построение декартова дерева
- Алгоритм за [math]O(n\log n)[/math]
- Другой алгоритм за [math]O(n\log n)[/math]
- Алгоритм за [math]O(n)[/math]
- Случайные приоритеты
- Высота в декартовом дереве с случайными приоритетами
- См. также
- Источники информации
Декартово дерево
Декартово дерево или дерамида (англ. Treap) — это структура данных, объединяющая в себе бинарное дерево поиска и бинарную кучу (отсюда и второе её название: treap (tree + heap) и дерамида (дерево + пирамида), также существует название курево (куча + дерево).
Более строго, это бинарное дерево, в узлах которого хранятся пары [math] (x,y) [/math] , где [math]x[/math] — это ключ, а [math]y[/math] — это приоритет. Также оно является двоичным деревом поиска по [math]x[/math] и пирамидой по [math]y[/math] . Предполагая, что все [math]x[/math] и все [math]y[/math] являются различными, получаем, что если некоторый элемент дерева содержит [math](x_0,y_0)[/math] , то у всех элементов в левом поддереве [math]x \lt x_0[/math] , у всех элементов в правом поддереве [math] x \gt x_0[/math] , а также и в левом, и в правом поддереве имеем: [math] y \lt y_0[/math] .
Дерамиды были предложены Сиделем (Siedel) и Арагон (Aragon) в 1996 г.
Операции в декартовом дереве
split
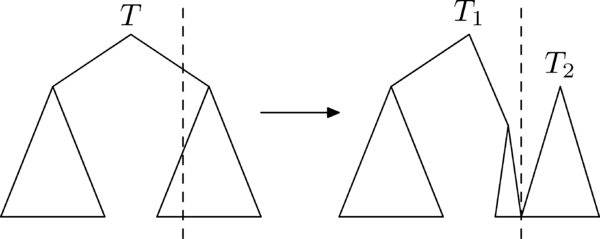
Операция [math]\mathrm[/math] (разрезать) позволяет сделать следующее: разрезать исходное дерево [math]T[/math] по ключу [math]k[/math] . Возвращать она будет такую пару деревьев [math]\langle T_1, T_2\rangle [/math] , что в дереве [math]T_1[/math] ключи меньше [math]k[/math] , а в дереве [math]T_2[/math] все остальные: [math]\mathrm(T, k) \to \langle T_1, T_2\rangle [/math] .
Эта операция устроена следующим образом.
Рассмотрим случай, в котором требуется разрезать дерево по ключу, большему ключа корня. Посмотрим, как будут устроены результирующие деревья [math]T_1[/math] и [math]T_2[/math] :
- [math]T_1[/math] : левое поддерево [math]T_1[/math] совпадёт с левым поддеревом [math]T[/math] . Для нахождения правого поддерева [math]T_1[/math] , нужно разрезать правое поддерево [math]T[/math] на [math]T^R_1[/math] и [math]T^R_2[/math] по ключу [math]k[/math] и взять [math]T^R_1[/math] .
- [math]T_2[/math] совпадёт с [math]T^R_2[/math] .
Случай, в котором требуется разрезать дерево по ключу, меньше либо равному ключа в корне, рассматривается симметрично.
Псевдокод
Treap, Treap split(t: Treap, k: int): if t == return , else if k > t.x t1, t2 = split(t.right, k) t.right = t1 return t, t2 else t1, t2 = split(t.left, k) t.left = t2 return t1, t
Время работы
Оценим время работы операции [math]\mathrm[/math] . Во время выполнения вызывается одна операция [math]\mathrm[/math] для дерева хотя бы на один меньшей высоты и делается ещё [math]O(1)[/math] операций. Тогда итоговая трудоёмкость этой операции равна [math]O(h)[/math] , где [math]h[/math] — высота дерева.
merge
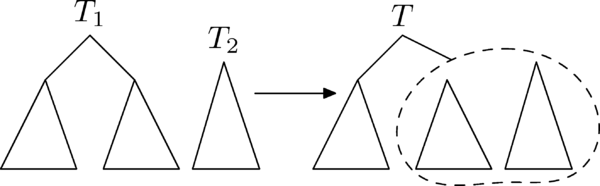
Рассмотрим вторую операцию с декартовыми деревьями — [math]\mathrm[/math] (слить).
С помощью этой операции можно слить два декартовых дерева в одно. Причём, все ключи в первом(левом) дереве должны быть меньше, чем ключи во втором(правом). В результате получается дерево, в котором есть все ключи из первого и второго деревьев: [math]\mathrm(T_1, T_2) \to \[/math]
Рассмотрим принцип работы этой операции. Пусть нужно слить деревья [math]T_1[/math] и [math]T_2[/math] . Тогда, очевидно, у результирующего дерева [math]T[/math] есть корень. Корнем станет вершина из [math]T_1[/math] или [math]T_2[/math] с наибольшим приоритетом [math]y[/math] . Но вершина с самым большим [math]y[/math] из всех вершин деревьев [math]T_1[/math] и [math]T_2[/math] может быть только либо корнем [math]T_1[/math] , либо корнем [math]T_2[/math] . Рассмотрим случай, в котором корень [math]T_1[/math] имеет больший [math]y[/math] , чем корень [math]T_2[/math] . Случай, в котором корень [math]T_2[/math] имеет больший [math]y[/math] , чем корень [math]T_1[/math] , симметричен этому.
Если [math]y[/math] корня [math]T_1[/math] больше [math]y[/math] корня [math]T_2[/math] , то он и будет являться корнем. Тогда левое поддерево [math]T[/math] совпадёт с левым поддеревом [math]T_1[/math] . Справа же нужно подвесить объединение правого поддерева [math]T_1[/math] и дерева [math]T_2[/math] .
Псевдокод
Treap merge(t1: Treap, t2: Treap): if t2 == return t1 if t1 == return t2 else if t1.y > t2.y t1.right = merge(t1.right, t2) return t1 else t2.left = merge(t1, t2.left) return t2
Время работы
Рассуждая аналогично операции [math]\mathrm[/math] , приходим к выводу, что трудоёмкость операции [math]\mathrm[/math] равна [math]O(h)[/math] , где [math]h[/math] — высота дерева.
insert
Операция [math]\mathrm(T, k)[/math] добавляет в дерево [math]T[/math] элемент [math]k[/math] , где [math]k.x[/math] — ключ, а [math]k.y[/math] — приоритет.
Представим что элемент [math]k[/math] , это декартово дерево из одного элемента, и для того чтобы его добавить в наше декартово дерево [math]T[/math] , очевидно, нам нужно их слить. Но [math]T[/math] может содержать ключи как меньше, так и больше ключа [math]k.x[/math] , поэтому сначала нужно разрезать [math]T[/math] по ключу [math]k.x[/math] .
- Реализация №1
- Разобьём наше дерево по ключу, который мы хотим добавить, то есть [math]\mathrm(T, k.x) \to \langle T_1, T_2\rangle[/math] .
- Сливаем первое дерево с новым элементом, то есть [math]\mathrm(T_1, k) \to T_1[/math] .
- Сливаем получившиеся дерево со вторым, то есть [math]\mathrm(T_1, T_2) \to T[/math] .
- Реализация №2
- Сначала спускаемся по дереву (как в обычном бинарном дереве поиска по [math]k.x[/math] ), но останавливаемся на первом элементе, в котором значение приоритета оказалось меньше [math]k.y[/math] .
- Теперь вызываем [math]\mathrm(T, k.x) \to \langle T_1, T_2\rangle[/math] от найденного элемента (от элемента вместе со всем его поддеревом)
- Полученные [math]T_1[/math] и [math]T_2[/math] записываем в качестве левого и правого сына добавляемого элемента.
- Полученное дерево ставим на место элемента, найденного в первом пункте.
В первой реализации два раза используется [math]\mathrm[/math] , а во второй реализации слияние вообще не используется.
remove
Операция [math]\mathrm(T, x)[/math] удаляет из дерева [math]T[/math] элемент с ключом [math]x[/math] .
- Реализация №1
- Разобьём наше дерево по ключу, который мы хотим удалить, то есть [math]\mathrm(T, k.x) \to \langle T_1, T_2\rangle[/math] .
- Теперь отделяем от первого дерева элемент [math]x[/math] , то есть самого левого ребёнка дерева [math] T_2 [/math] .
- Сливаем первое дерево со вторым, то есть [math]\mathrm(T_1, T_2) \to T[/math] .
- Реализация №2
- Спускаемся по дереву (как в обычном бинарном дереве поиска по [math]x[/math] ), и ищем удаляемый элемент.
- Найдя элемент, вызываем [math]\mathrm[/math] его левого и правого сыновей
- Результат процедуры [math]\mathrm[/math] ставим на место удаляемого элемента.
В первой реализации один раз используется [math]\mathrm[/math] , а во второй реализации разрезание вообще не используется.
Построение декартова дерева
Пусть нам известно из каких пар [math](x_i, y_i)[/math] требуется построить декартово дерево, причём также известно, что [math]x_1 \lt x_2 \lt \ldots \lt x_n[/math] .
Алгоритм за [math]O(n\log n)[/math]
Отсортируем все приоритеты по убыванию за [math] O(n\log n) [/math] и выберем первый из них, пусть это будет [math]y_k[/math] . Сделаем [math](x_k, y_k)[/math] корнем дерева. Проделав то же самое с остальными вершинами получим левого и правого сына [math](x_k, y_k)[/math] . В среднем высота Декартова дерева [math]\log n[/math] (см. далее) и на каждом уровне мы сделали [math]O(n)[/math] операций. Значит такой алгоритм работает за [math]O(n\log n)[/math] .
Другой алгоритм за [math]O(n\log n)[/math]
Отсортируем пары [math](x_i, y_i)[/math] по убыванию [math]x_i[/math] и положим их в очередь. Сперва достанем из очереди первые [math]2[/math] элемента и сольём их в дерево и положим в конец очереди, затем сделаем то же самое со следующими двумя и т.д. Таким образом, мы сольём сначала [math]n[/math] деревьев размера [math]1[/math] , затем [math]\dfrac[/math] деревьев размера [math]2[/math] и так далее. При этом на уменьшение размера очереди в два раза мы будем тратить суммарно [math]O(n)[/math] время на слияния, а всего таких уменьшений будет [math]\log n[/math] . Значит полное время работы алгоритма будет [math]O(n\log n)[/math] .
Алгоритм за [math]O(n)[/math]
Будем строить дерево слева направо, то есть начиная с [math](x_1, y_1)[/math] по [math](x_n, y_n)[/math] , при этом помнить последний добавленный элемент [math](x_k, y_k)[/math] . Он будет самым правым, так как у него будет максимальный ключ, а по ключам декартово дерево представляет собой двоичное дерево поиска. При добавлении [math](x_, y_)[/math] , пытаемся сделать его правым сыном [math](x_k, y_k)[/math] , это следует сделать если [math]y_k \gt y_[/math] , иначе делаем шаг к предку последнего элемента и смотрим его значение [math]y[/math] . Поднимаемся до тех пор, пока приоритет в рассматриваемом элементе меньше приоритета в добавляемом, после чего делаем [math](x_, y_)[/math] его правым сыном, а предыдущего правого сына делаем левым сыном [math](x_, y_)[/math] .
Заметим, что каждую вершину мы посетим максимум дважды: при непосредственном добавлении и, поднимаясь вверх (ведь после этого вершина будет лежать в чьём-то левом поддереве, а мы поднимаемся только по правому). Из этого следует, что построение происходит за [math]O(n)[/math] .
Случайные приоритеты
Мы уже выяснили, что сложность операций с декартовым деревом линейно зависит от его высоты. В действительности высота декартова дерева может быть линейной относительно его размеров. Например, высота декартова дерева, построенного по набору ключей [math](1, 1), \ldots, (n, n)[/math] , будет равна [math]n[/math] . Во избежание таких случаев, полезным оказывается выбирать приоритеты в ключах случайно.
Высота в декартовом дереве с случайными приоритетами
В декартовом дереве из [math]n[/math] узлов, приоритеты [math]y[/math] которого являются случайными величинами c равномерным распределением, средняя глубина вершины [math]O(\log n)[/math] .
Будем считать, что все выбранные приоритеты [math]y[/math] попарно различны.
Для начала введём несколько обозначений:
- [math]x_k[/math] — вершина с [math]k[/math] -ым по величине ключом;
- индикаторная величина [math]A_ = \left\1 ,&& x_i\ \text \ x_j\\ 0 ,&& \text\\ \end\right. [/math]
- [math]d(v)[/math] — глубина вершины [math]v[/math] ;
В силу обозначений глубину вершины можно записать как количество предков:
[math]d(x_k) = \sum\limits_^ A_ [/math] .
Теперь можно выразить математическое ожидание глубины конкретной вершины:
[math]E(d(x_k)) = \sum\limits_^ Pr[A_ = 1] [/math] — здесь мы использовали линейность математического ожидания, и то что [math]E(X) = Pr[X = 1][/math] для индикаторной величины [math]X[/math] ( [math]Pr[A][/math] — вероятность события [math]A[/math] ).
Для подсчёта средней глубины вершин нам нужно сосчитать вероятность того, что вершина [math]x_i[/math] является предком вершины [math]x_k[/math] , то есть [math]Pr[A_ = 1][/math] .
- [math]X_[/math] — множество ключей [math]\[/math] или [math]\[/math] , в зависимости от [math]i \lt k[/math] или [math]i \gt k[/math] . [math]X_[/math] и [math]X_[/math] обозначают одно и тоже, их мощность равна [math]|k — i| + 1[/math] .
Для любых [math]i \ne k[/math] , [math]x_i[/math] является предком [math]x_k[/math] тогда и только тогда, когда [math]x_i[/math] имеет наибольший приоритет среди [math]X_
Если [math]x_i[/math] является корнем, то оно является предком [math]x_k[/math] и по определению имеет максимальный приоритет среди всех вершин, следовательно, и среди [math]X_[/math] .
С другой стороны, если [math]x_k[/math] — корень, то [math]x_i[/math] — не предок [math]x_k[/math] , и [math]x_k[/math] имеет максимальный приоритет в декартовом дереве; следовательно, [math]x_i[/math] не имеет наибольший приоритет среди [math]X_[/math] .
Теперь предположим, что какая-то другая вершина [math]x_m[/math] — корень. Тогда, если [math]x_i[/math] и [math]x_k[/math] лежат в разных поддеревьях, то [math]i \lt m \lt k[/math] или [math]i \gt m \gt k[/math] , следовательно, [math]x_m[/math] содержится в [math]X_[/math] . В этом случае [math]x_i[/math] — не предок [math]x_k[/math] , и наибольший приоритет среди [math]X_[/math] имеет вершина с номером [math]m[/math] .
Так как распределение приоритетов равномерное, каждая вершина среди [math]X_[/math] может иметь максимальный приоритет, мы немедленно приходим к следующему равенству:
Подставив последнее в нашу формулу с математическим ожиданием получим:
[math]E(d(x_k)) = \sum\limits_^ Pr[A_ = 1] = \sum\limits_^\dfrac + \sum\limits_^\dfrac \leqslant [/math]
[math]\leqslant \ln(k) + \ln(n — k)+2[/math] (здесь мы использовали неравенство [math]\sum\limits_^ \dfrac \leqslant \ln(n) + 1[/math] )
Таким образом, среднее время работы операций [math]\mathrm[/math] и [math]\mathrm[/math] будет [math]O(\log(n))[/math] .
См. также
Источники информации
Источник